
1. UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。
UTF-8就是为了解决向后兼容ASCII码而设计,Unicode中前128个字符,使用与ASCII码相同的二进制值的单个字节进行编码,而且字面与ASCII码的字面一一对应,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式
1.2 结构
UTF-8使用一至六个字节为每个字符编码(尽管如此,2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节):
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要两个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
- 其他极少使用的Unicode 辅助平面的字符使用四至六字节编码(Unicode范围由U+10000至U+1FFFFF使用四字节,Unicode范围由U+200000至U+3FFFFFF使用五字节,Unicode范围由U+4000000至U+7FFFFFFF使用六字节)。
对上述提及的第四种字符而言,UTF-8使用四至六个字节来编码似乎太耗费资源了。但UTF-8对所有常用的字符都可以用三个字节表示,而且它的另一种选择,UTF-16编码,对前述的第四种字符同样需要四个字节来编码,所以要决定UTF-8或UTF-16哪种编码比较有效率,还要视所使用的字符的分布范围而定。不过,如果使用一些传统的压缩系统,比如DEFLATE,则这些不同编码系统间的的差异就变得微不足道了。
1.3 字节含义
- 对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
- 如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
- 如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
- 如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
- 如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节;

1.4 编码方式
UTF-8就是以8位为单元对UCS进行编码,而UTF-8不使用大尾序和小尾序的形式,每个使用UTF-8存储的字符,除了第一个字节外,其余字节的头两个比特都是以"10"开始,使文字处理器能够较快地找出每个字符的开始位置。
但为了与以前的ASCII码兼容(ASCII为一个字节),因此UTF-8选择了使用可变长度字节来存储Unicode:

在UTF-8+BOM格式文件的开首,很多时都放置一个U+FEFF字符(UTF-8以EF,BB,BF代表),以显示这个文本文件是以UTF-8编码。
2. UTF-16
即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
两个至四个字节,编码空间从U+0000到U+10FFFF,共有1,112,064个码位(code point)可用来映射字符。
2.1 编码规则
UTF-16利用Unicode基本多语言平面内(第零平面)保留下来的0xD800-0xDFFF区块的码位来对辅助平面的字符的码位进行编码。
-
从U+0000至U+D7FF以及从U+E000至U+FFFF的码位
第一个Unicode平面(码位从U+0000至U+FFFF)包含了最常用的字符,该平面被称为基本多语言平面,缩写为BMP。UTF-16与UCS-2编码这个范围内的码位为16比特长的单个码元,数值等价于对应的码位。BMP中的这些码位是仅有的可以在UCS-2中表示的码位。 -
从U+10000到U+10FFFF的码位
辅助平面(Supplementary Planes)中的码位,在UTF-16中被编码为一对16比特长的码元(即32位,4字节),称作代理对(Surrogate Pair),具体方法是:
- 码位减去 0x10000,得到的值的范围为20比特长的 0…0xFFFFF。
- 高位的10比特的值(值的范围为 0…0x3FF)被加上 0xD800 得到第一个码元或称作高位代理(high surrogate),值的范围是 0xD800…0xDBFF。由于高位代理比低位代理的值要小,所以为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogates)。
- 低位的10比特的值(值的范围也是 0…0x3FF)被加上 0xDC00 得到第二个码元或称作低位代理(low surrogate),现在值的范围是 0xDC00…0xDFFF。由于低位代理比高位代理的值要大,所以为了避免混淆使用,Unicode标准现在称低位代理为后尾代理(trail surrogates)。
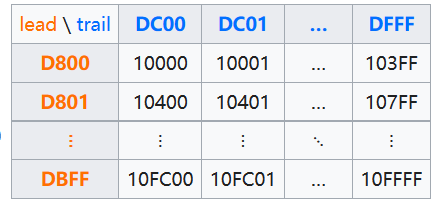
- 从U+D800到U+DFFF的码位
Unicode标准规定U+D800…U+DFFF的值不对应于任何字符。
3. UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 码即可,不需要任何编码转换。虽然浪费了空间,但提高了效率。
4. UTF编码字节序
最小编码单元是多字节才会有字节序的问题
- UTF-8 最小编码单元是一字节,所以 它是没有字节序的问题
- UTF-16 最小编码单元是 2 个字节,在解析一个 UTF-16 字符之前,需要知道每个编码单元的字节序
- UTF-16 最小编码单元是 4 个字节,也需要知道字节序
小端字节序简写为 LE( Little-Endian ), 表示 低位字节在前,高位字节在后, 高位字节保存在内存的高地址端,而低位字节保存在内存的低地址端
大端字节序简写为 BE( Big-Endian ), 表示 高位字节在前,低位字节在后,高位字节保存在内存的低地址端,低位字节保存在在内存的高地址端
BOM 是 byte-order mark 的缩写,是 “字节序标记” 的意思, 它常被用来当做标识文件是以 UTF-8、UTF-16 或 UTF-32 编码的标记
在 Unicode 编码中有一个叫做 “零宽度非换行空格” 的字符 ( ZERO WIDTH NO-BREAK SPACE ), 用字符 FEFF 来表示
对于 UTF-16 ,如果接收到以 FEFF 开头的字节流, 就表明是大端字节序,如果接收到 FFFE, 就表明字节流 是小端字节序
5. MySQL 中的 utf8 和 utf8mb4
MySQL 中的 “utf8” 实际上不是真正的 UTF-8, “utf8” 只支持每个字符最多 3 个字节, 对于超过 3 个字节的字符就会出错, 而真正的 UTF-8 至少要支持 4 个字节
MySQL 中的 “utf8mb4” 才是真正的 UTF-8