
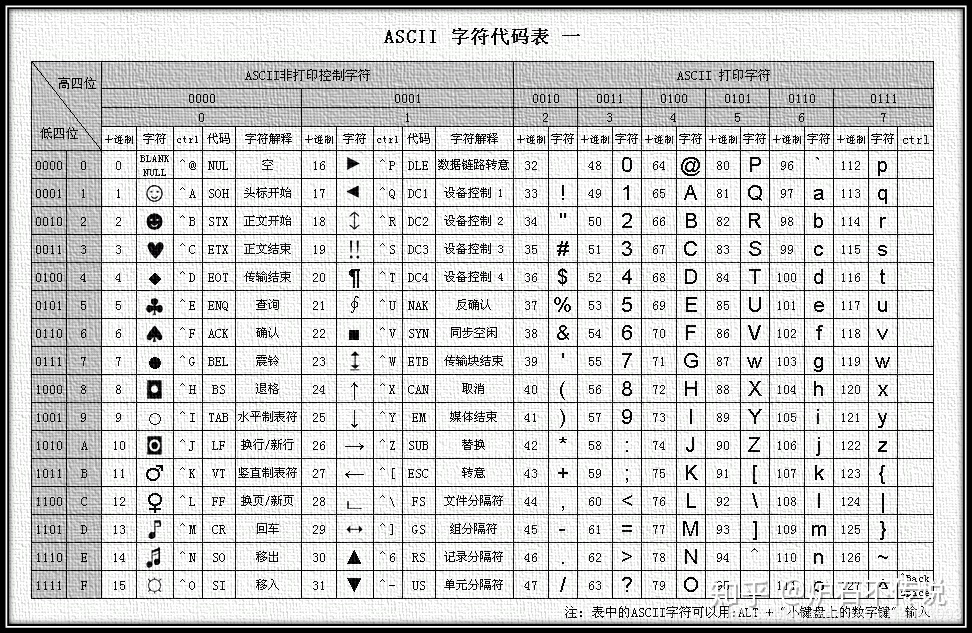
1. ASCII字符集
上个世纪60年代,美国制定了一套字符编码规则,对英语字符与二进制位之间的关系做了统一规定,这编码规则被称为ASCII编码,一直沿用至今。
ASCII编码占用一个字节,最高位统一规定0,用后面7位标识字符编码,总共128个(0-31是控制字符,32-126是打印字符)
2. ISO8859-1
英语用128位是够的,但到欧洲的时候,一些欧洲国家对ACII码进行了扩充. 利用字节中闲置的最高位进行扩充. 也就是0x80-0xFF这后面的128个字符进行定义.
ISO8859-1包含了256个字符,前128和ASCII一样

ISO8859-1 字符集,也就是 Latin-1,是西欧常用字符,包括德法两国的字母。
ISO8859-2 字符集,也称为 Latin-2,收集了东欧字符。
ISO8859-3 字符集,也称为 Latin-3,收集了南欧字符。
3. GB2312
当计算机引入中国后,为了显示中文,必须重新设计一套字符集(很明显,中国汉字远远超过128个)。 1980年由中国国家标准总局发布,取名为GB2312或GB2312-80。全称为《信息交换用汉字编码字符集·基本集》,1981年开始使用。
其中一级汉字3755个,二级汉字3008个。同时,GB2312编码收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符
有不少汉字,如"啰","镕"以及台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。
3.1 双字节编码
GB2312规定对收录的每个字符采用两个字节表示,
兼容ASCII字符集,GB2312规定一个小于127的字符的意义与原来相同。
但两个大于127的字符连在一起时,就表示一个GB2312字符
GB2312有两个字节,编码范围:A1A1-FEFE,其中汉字编码范围:B0A1-F7FE。
- 第一个字节为“高字节”,对应94个区;
- 第二个字节为“低字节”,对应94个位。所以它的区位码范围是:0101-9494。
- 区号和位号分别加上0xA0就是GB2312编码。
例如最后一个码位是9494,区号和位号分别转换成十六进制是5E5E,0x5E+0xA0=0xFE,所以该码位的GB2312编码是FEFE。
3.2 分区表示
GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。这种表示方式也称为区位码。
- 01-09区收录除汉字外的682个字符。
- 10-15区为空白区,没有使用。
- 16-55区收录3755个一级汉字,按拼音排序。
- 56-87区收录3008个二级汉字,按部首/笔画排序。
- 88-94区为空白区,没有使用。
举例来说,“啊”字是GB2312编码中的第一个汉字,它位于16区的01位,所以它的区位码就是1601。
4. GBK
GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
但对于人名、古汉语等方面出现的罕用字和繁体字,GB2312不能处理,于是对其进行扩展形成了GBK编码,由全国信息技术标准化技术委员会1995年12月1日制订。
GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个
兼容GB2312和ASCII
4.1 编码方式
字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致
之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。
4.2 编码范围
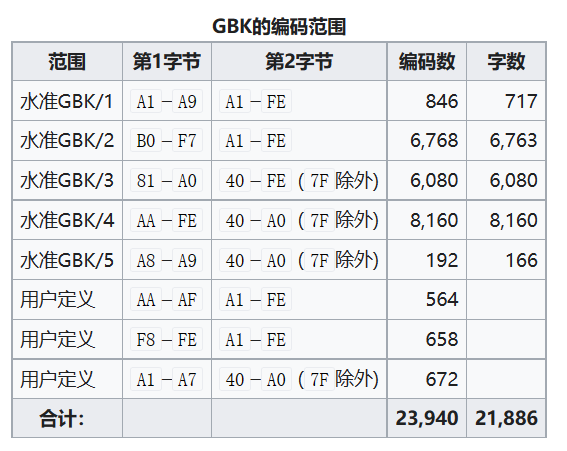
上述GBK/1和GBK/2的领域即GB 2312-80用通常方法编码的区域。
GB 2312是从A1–FE的范围开始读取字节对,但是AA–AF和F8–FE区域是空的,没有赋予编码。于是GBK就在这些领域里进行拓展。二者剩余部分作为用户定义区。
5. Unicode
20世纪80年代末,组成Unicode组织的商业机构,和国际合作的国际标准化组织在电脑普及和信息国际化的前提下,分别各自成立了Unicode组织和ISO-10646工作小组。
虽然实际上两者的字集编码相同,但本质上两者确为不同的标准。Unicode 1.1对应于ISO 10646-1:1993,Unicode 3.0对应于ISO 10646-1:2000,Unicode 3.2对应于ISO 10646-2:2001,Unicode 4.0对应于ISO 10646:2003,Unicode 5.0对应于ISO 10646:2003及附录1–3。
大概介绍下时间点
1991年10月发布1.00版本,大概7千个字符
1992年6月发布1.0.1版,包含2万多个字符(定义中日韩一表意文字CJK)
‘’’
5.1 十大设计原则
- Universality:提供单一、综合的字符集,编码一切现代与大部分历史文献的字符。
- Efficiency:易于处理与分析。
- Characters, not glyphs:字符,而不是字形。
- Semantics:字符要有良好定义的语义。
- Plain text:仅限于文本字符。
- Logical order:默认内存表示是其逻辑序。
- Unification:把不同语言的同一书写系统(scripts)中相同字符统一起来。
- Dynamic composition:附加符号可以动态组合。
- Stability:已分配的字符与语义不再改变。
- Convertibility:Unicode与其他著名字符集可以精确转换。
5.2 编码方式
目前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示216(即65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
上述16位统一码字符构成基本多文种平面。最新(但未实际广泛使用)的统一码版本定义了16个辅助平面,两者合起来至少需要占据21位的编码空间,比3字节略少。但事实上辅助平面字符仍然占用4字节编码空间,与UCS-4保持一致。未来版本会扩充到ISO 10646-1实现级别3,即涵盖UCS-4的所有字符。UCS-4是更大而尚未填充完全的31位字符集,加上恒为0的首位,共需占据32位,即4字节。理论上最多能表示231个字符,完全可以涵盖一切语言所用的符号。
基本多文种平面的字符的编码为U+hhhh,其中每个h代表一个十六进制数字,与UCS-2编码完全相同。而其对应的4字节UCS-4编码后两个字节一致,前两个字节则所有位均为0。
5.3 实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码确定。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
- UTF编码
例如,如果一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0。这就造成了比较大的浪费。对于这种情况,可以使用UTF-8编码,这是变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他Unicode字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1识别。这样对以7位ASCII字符为主的西文文档就大幅节省了编码长度(具体方案参见UTF-8)。类似的,对未来会出现的需要4个字节的辅助平面字符和其他UCS-4扩充字符,2字节编码的UTF-16也需要通过一定的算法转换。
此外Unicode的实现方式还包括UTF-7、Punycode、CESU-8、SCSU、UTF-32、GB18030等,这些实现方式有些仅在一定的国家和地区使用,有些则属于未来的规划方式。
目前通用的实现方式是UTF-16小端序(LE)、UTF-16大端序(BE)和UTF-8
5.4字符平面映射
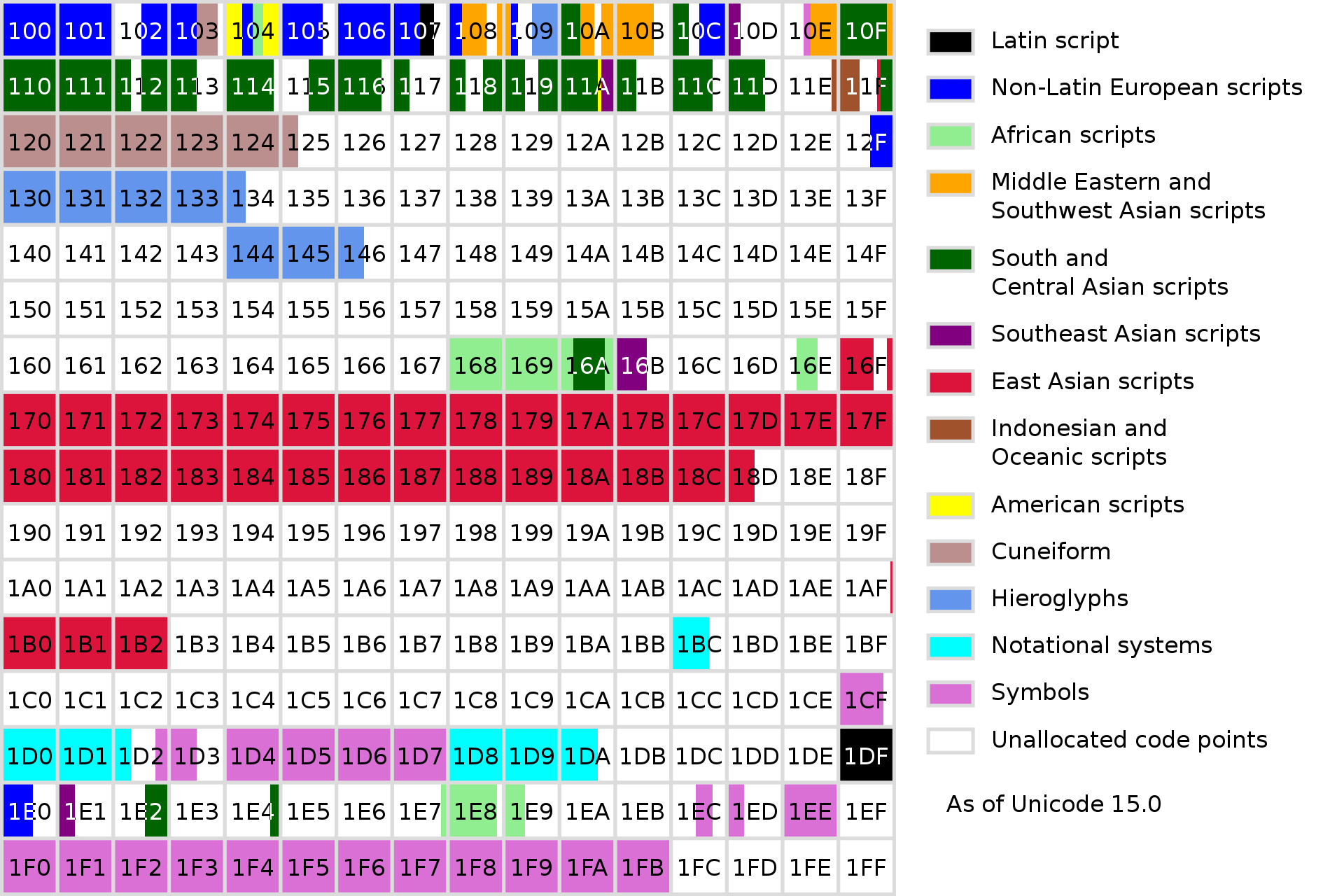
Unicode 将编码空间分成 17 个平面,以 0 到 16 编号。
第 0 平面(或者说基本多文种平面)中的码点,都可以用一个 UTF-16 单位来编码,或者以 UTF-8 来编码的话,会使用一、二或三个字节。而第 1 到 16 平面(或称辅助平面)中的码点,UTF-16 会以代理对的方式来使用,而 UTF-8 则会编码成 4 个字节。
在每个平面中,会先将相关的字符集结为区段的形式。虽然区段可以是任意大小,但会以 16 个码点的倍数,且通常是 128 个码点的倍数。而一份文稿中使用到的区段,可能会散布在多个区段中。
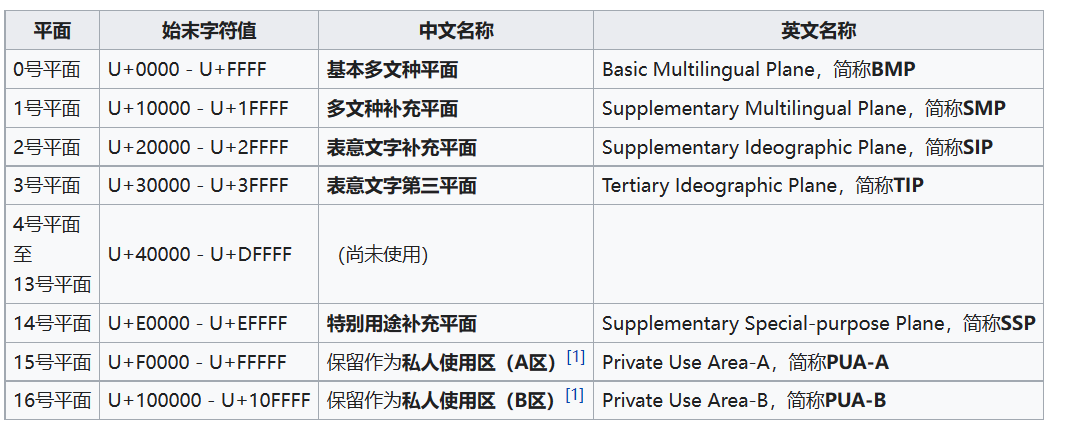
- 基本多文种平面(Basic Multilingual Plane, BMP),或称基本平面或0号平面(Plane 0),是Unicode中的一个编码区块。编码从U+0000至U+FFFF。
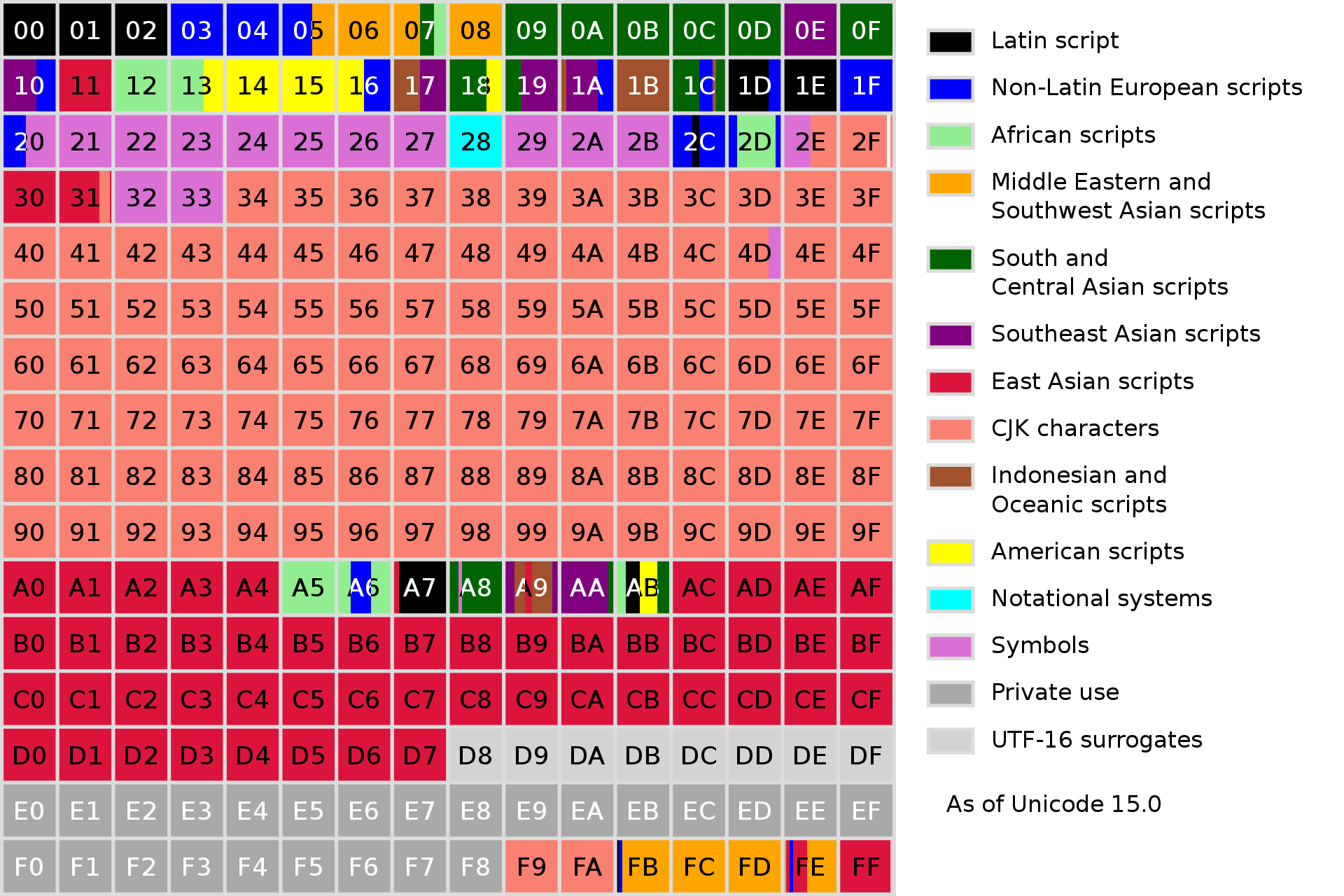
- 第一辅助平面又称多文种补充平面(Supplementary Multilingual Plane,缩写SMP,或简称Plane 1),主要摆放绝大多数古代文字,现时已不再使用或很少使用文字、速记、数学字母符号、音符、图形符号及用于学者的专业论文中使用的古老或过时的语言书写符号,以及网络通信等使用的绘文字。范围在U+10000~U+1FFFF。计划分配如下。
- 第二辅助平面又称为表意文字补充平面(Supplementary Ideographic Plane,缩写SIP,或简称Plane 2),整个范围在U+20000~U+2FFFF。整个平面配置的都是一些罕用的汉字或地区的方言用字,如粤语用字及越南语的字喃。现时摆放了“中日韩统一表意文字扩展B区”(4万3253个汉字)、“中日韩统一表意文字扩展C区”(4149个汉字)、“中日韩统一表意文字扩展D区”(222个汉字)、“中日韩统一表意文字扩展E区”(5762个汉字)、“中日韩统一表意文字扩展F区”(7473个汉字)以及中日韩兼容表意文字增补(CJK Compatibility Ideographs Supplement)。
已分配的编码区段为:
- 中日韩统一表意文字扩展B区(20000-2A6DF)
- 中日韩统一表意文字扩展C区(2A700-2B73F)
- 中日韩统一表意文字扩展D区(2B740-2B81F)
- 中日韩统一表意文字扩展E区(2B820-2CEAF)
- 中日韩统一表意文字扩展F区(2CEB0-2EBEF)
- 中日韩兼容表意文字增补(2F800-2FA1F)

- 第三辅助平面已有相关编码提案。本平面现已用来摆放汉字扩展区G和H,并规划用于摆放甲骨文、金文、小篆、中国战国时期文字等,范围在U+30000~U+3FFFF。
已分配的编码区段为:
- 中日韩统一表意文字扩展G区(30000-3134F)
- 中日韩统一表意文字扩展H区(31350-323AF)

- 第四至十三辅助平面 尚无使用计划
- 第十四辅助平面
又称特别用途补充平面(Supplementary Special-purpose Plane,简称SSP),目前仅摆放“语言编码标签”和“字形变换选取器”,它们都是控制字符。范围在U+E0000~U+E01FF。
- 标签(E0000-E007F)
- 选择器变化补充(E0100-E01EF)

6. GB18030
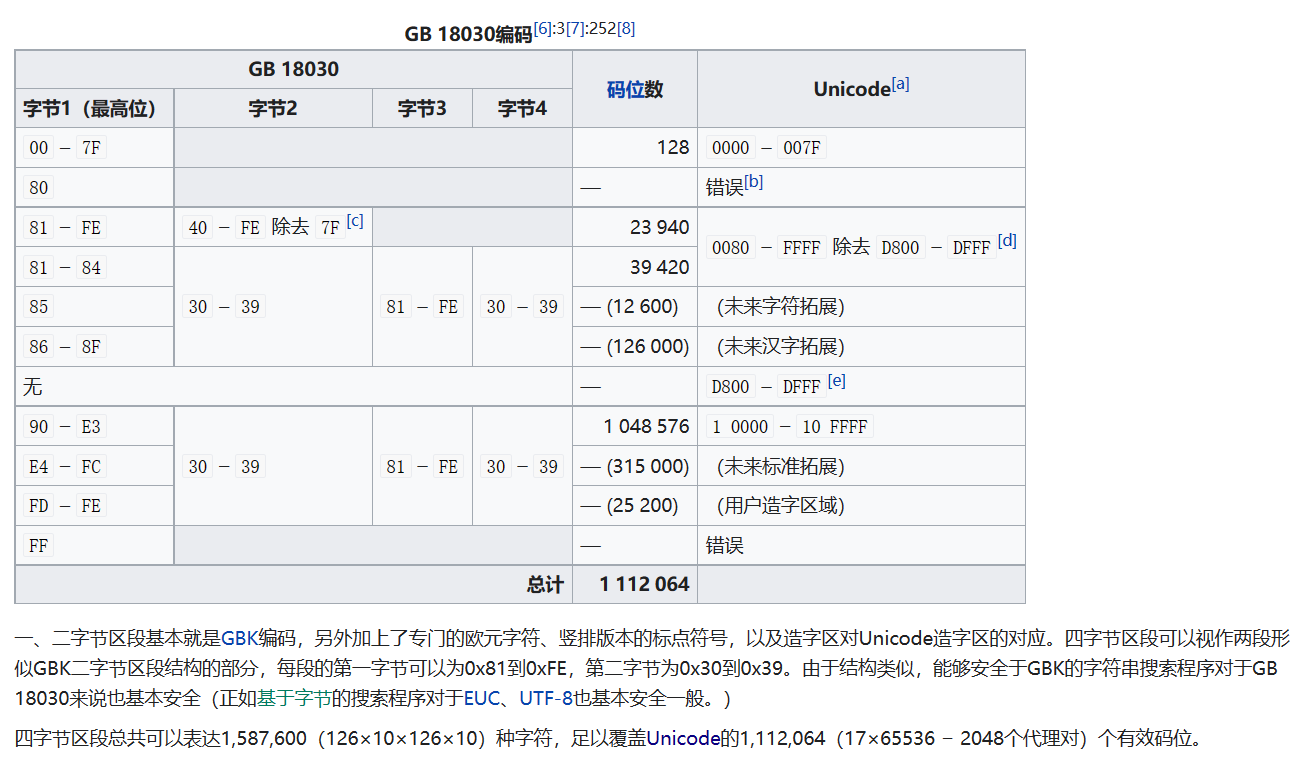
GB18030是变长多字节字符集,变长多字节编码,每个字可以由1个、2个或4个字节组成。
编码空间庞大,最多可定义161万个字元。
无需动用造字区即可支持中国国內少数民族文字、中日韩和繁体汉字以及emoji等字符
- 第一版 GB 18030-2000,该标准在GBK基础上增加了CJK统一汉字扩充A的汉字。2000年3月17日发布和实施. 兼容Unicode3.0
目前废止状态。
- 第二版为 GB 18030-2005,是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字. 共收录汉字70,244个. 于2005年11月8日发布,2006年5月1日实施. 兼容Unicode3.1
此标准内的单字节编码部分、双字节编码部分,和四字节编码部分收录的少数中日韩统一表意文字扩展A区汉字,为强制性标准
- 第三版本 GB 18030-2022, 于2022年7月19日发布、2023年8月1日实施. 更新至Unicode11
共收录汉字87,887个和汉字部首228个,比上一版增加录入了1.7万余个生僻汉字;
6.1 编码结构
包含三种长度的编码:
- 单字节的ASCII
- 双字节的GBK(略带扩展)
- 以及用于填补所有Unicode码位的四字节UTF区段。
GBK双字节部分通过查表定义,而四字节部分则根据之前两个部分没有提到的通用字符集码位顺序填补。由于和GBK兼容,GB 18030在搜索ASCII字符时也需要使用特别代码进行判断。
6.2 和其它字符集的关系
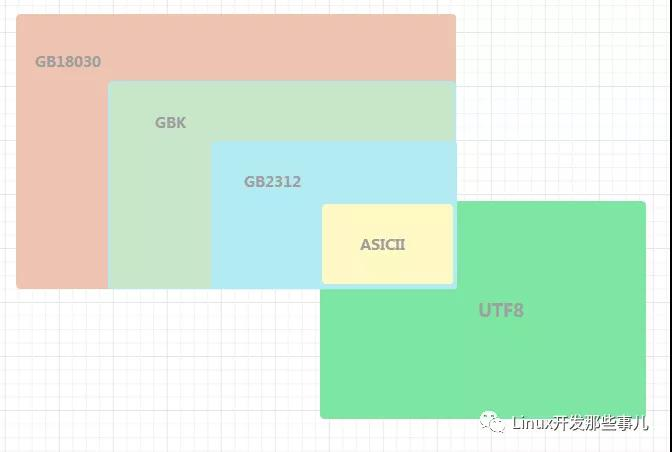
GB18030 和 Unicode 相当于两套单独的编码体系,它们都对世界上大部分字符进行编码,赋予每个字符一个唯一的编号,只不过对于同一个字符,GB18030 和 Unicode 对应的编号是不一样的, 比如:汉字 “中” 字的 GB18030 编码是 0xD6D0, 对应的 Unicode 码元是 0x4E2D, 从这一点上可以认为 GB18030 是一种 Unicode 的转换格式
GB18030 既是字符集又是编码格式,也即字符在字符集中的编号以及存储是进行编码用的编号是完全相同的,而 Unicode 仅仅是字符集,它只规定了字符的唯一编号,它的存储是用其他的编码格式的,比如 UTF8、UTF16 等等
对于大部分中文字符来说,采用 GB18030 编码的话,只需两个字节,如果采用 UTF8 编码,就需要三个字节, 所以用 GB18030 存储和传输更节省空间