1. 起源
我们知道,计算机是美国人发明的,人家的英语体系总从来就只有26个英文字母和一些数字、特殊字符等,为了储存文字信息,于是使用了最早的ASCII码进行字符编码。
而后来由于计算机的普及,多国语言文字变得重要起来,于是多语言的特性成为了计算机的必备,各国进行各国的国家标准编码,中国的便是GB2312(1980年),而后1995年又颁布了《汉字编码扩展规范》(GBK),GBK与GB2312相兼容,但又增加了一些兼容汉字,方便了和Big5码等进行转换。这套GBK编码,逐渐成为了中国计算机的主流编码。
2. Unicode
从Windows NT/2000开如,Windows系统已经是一个标准的UNICODE系统,系统内部所有字符串存储及操作均使用UNICODE编码。
3. MBCS(Multi-Byte Character Set) (ANSI)
MBCS(Multi-Byte Chactacter System,即多字节字符系统),是所有多字节编码方案的总称,MBCS 编程主要用于为国际市场编写的应用程序。
由于往往是针对一国市场只有一种文字,那么为了节约资源,往往将这些文字用双字节或尽量少的字节的方式进行保存。
因为这些双字节文字和ANSI是混和在一起的,为了加以区别,Windows将这些字符的最高位置为1(即这些双字节文字的每个字节都>=127),所以这种表示法可以表示 127x127 约一万多种非ANSI文字 ,其本上可以表示任何一种语言的常用文字了。
于是,Windows为每一个区域版本,都制定了分别独立的文字编码,这就是MBCS(多字节码)。
4. CodePage
这些分页后的编码方式,都被保存成了不同的CodePage,例如中文就是大家熟知的CP936。要注意,这种编码方式是早期windows独有的,由于使用较早,应用也十分广泛,而CP936和GB2312-80在编码上则是几乎一样的(此处见Wiki百科——汉字内码扩展规范),后来扩展GBK后,CP936也进行了同样的扩展。
常见的CodePage
932 —日文
936 —简体中文(GBK)
949 —韩文950 —繁体中文(大五码)
1200 —UCS-2LE Unicode 小端序
1201 —UCS-2BE Unicode 大端序
1252 —西欧拉丁字母ISO-8859-1.
65000 — UTF-7 Unicode
65001 — UTF-8 Unicode
cmd中输入chcp可以获取codepage代码
5. 字符转换
字符的存储和显示是独立的. 使用UNICODE编码的Windows系统,“字符的显示”当然是UNICODE编码.
但“字符的存储”则由用户决定,可以是ANSI(GB2312, GBK, JIS……)、也可以是UTF-16、UTF-32、UTF-8等。
当采用非UNICODE编码时,Windows在显示时会先根据“代码页转换表”执行由ANSI——UNICODE的转换
6. 计算机是如何显示文字
计算机要对文字进行存储后就需要显示出来,而我们的液晶屏都是一个个的像素点组成的,这就必须要对文字进行渲染绘制,发送到显卡中进行栅格化和显示等操作。
Dos下最简单,利用主板BIOS就能对ascii码进行点阵化输出。简单的我们就不再多谈,windows下是如何对文字进行绘制显示的呢?
6.1 字库

我们都知道,显示字体除了要有文字的编码,还需要有显示用的字的样式,这就是 字库,windows下的fonts文件夹大家应该都十分熟悉,更改或删除字库就是就是文件的移动而已。而字库实际上也有不同的种类的,构建原理也不都相同。
- 点阵字库: 最早的字库是点阵字库,这种字库看起来和黑白图片貌似没有什么大区别,就是记录像素是黑还是白,我们用windows自带的字库编辑程序,就可以处理这种字库。
缺点也是显而易见的,首先是缩放不易,在小字体和大字体显示时都容易失真走样,而且占用空间较大
- 矢量轮廓字库: 这种字库是用的矢量图原理进行存储的,将外部边界抽象成数学上的矢量线段,可以方便的缩放旋转等操作。缺点则是连续性不好,放大后就变出行了折痕,效果不够理想
- 曲线轮廓字库: 这是通过直线和曲线段共同构造文字的方法,往往使用Bezier曲线对轮廓进行拟合,效果非常好,字体平滑美工,但惟独就是计算较为费时间。
- TrueType字形技术 TrueType采用几何学中二次B样条曲线及直线来描述字体的外形轮廓。由一些数学算法进行对应大小字体的生成,无论放大或缩小,字符总是光滑的。
TrueType字体与PostScript字体、OpenType字体是主要的三种计算机矢量字体(又称轮廓字体、描边字体),后缀.ttf。
虽然计算较快,但相比于PostScript字体,质量要差一些,特别是文字太小时,不够清晰。
所以字库一般会对小字体和常用打印字号制作对应的点阵字库,保证其精度,其他情况则使用TrueType字体。
- WOFF–WebOpen Font Format (.woff)
WOFF(Web开发字体格式)是一种专门为了Web而设计的字体格式标准,实际上是对于TrueType/OpenType等字体格式的封装,每个字体文件中含有字体以及针对字体的元数据(Metadata),字体文件被压缩,以便于网络传输。
7. 字体的显示流程
- 读取对编码
- 调用对应的CodePage进行编码索引查找
- 调用字库中的数据
- 渲染图形
8. Windows系统对中文的支持
windows系统的都是支持Unicode编码的,unicode包含全世界几乎所有的字符.
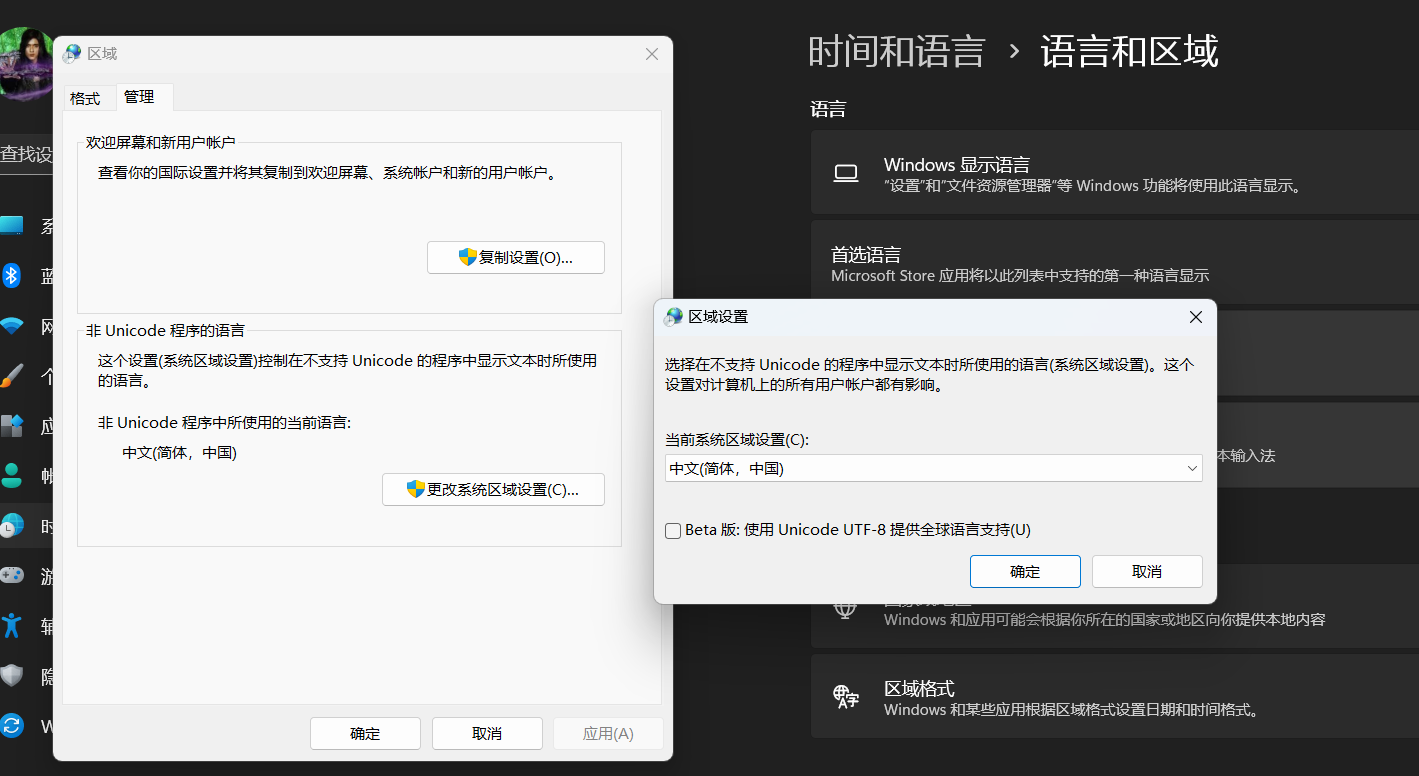
如果地区是非Unicode编码,也可以修改字符集设置
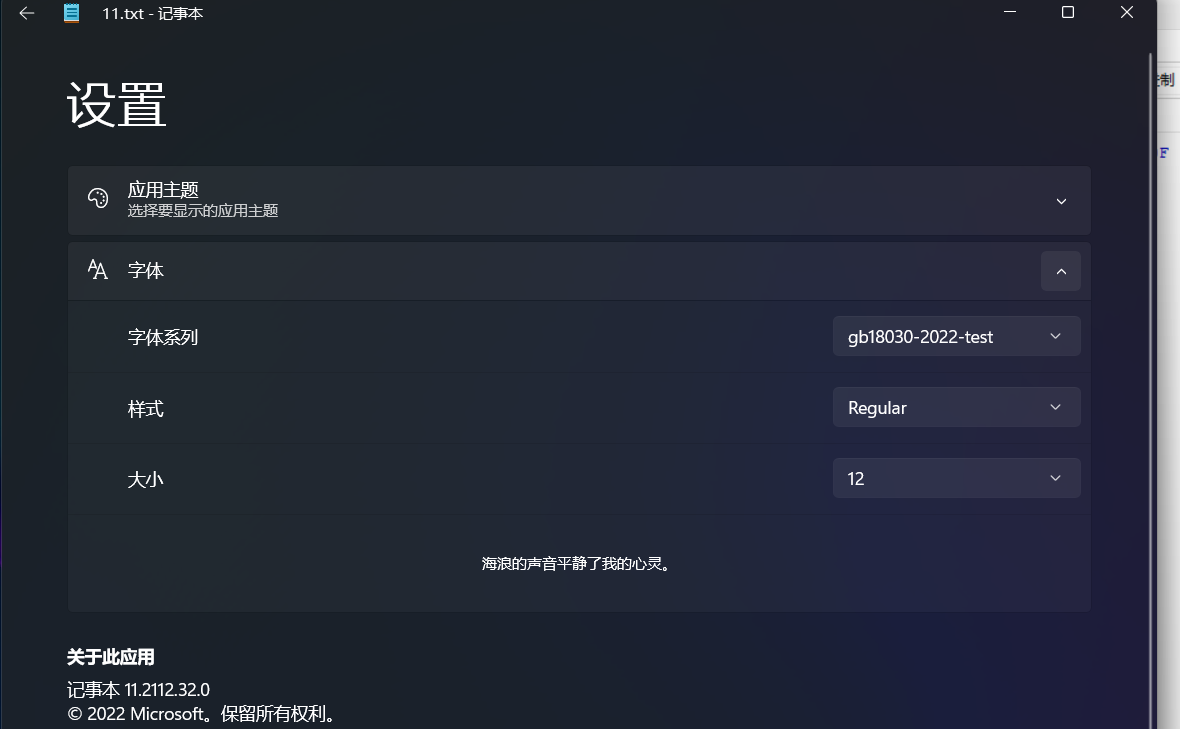
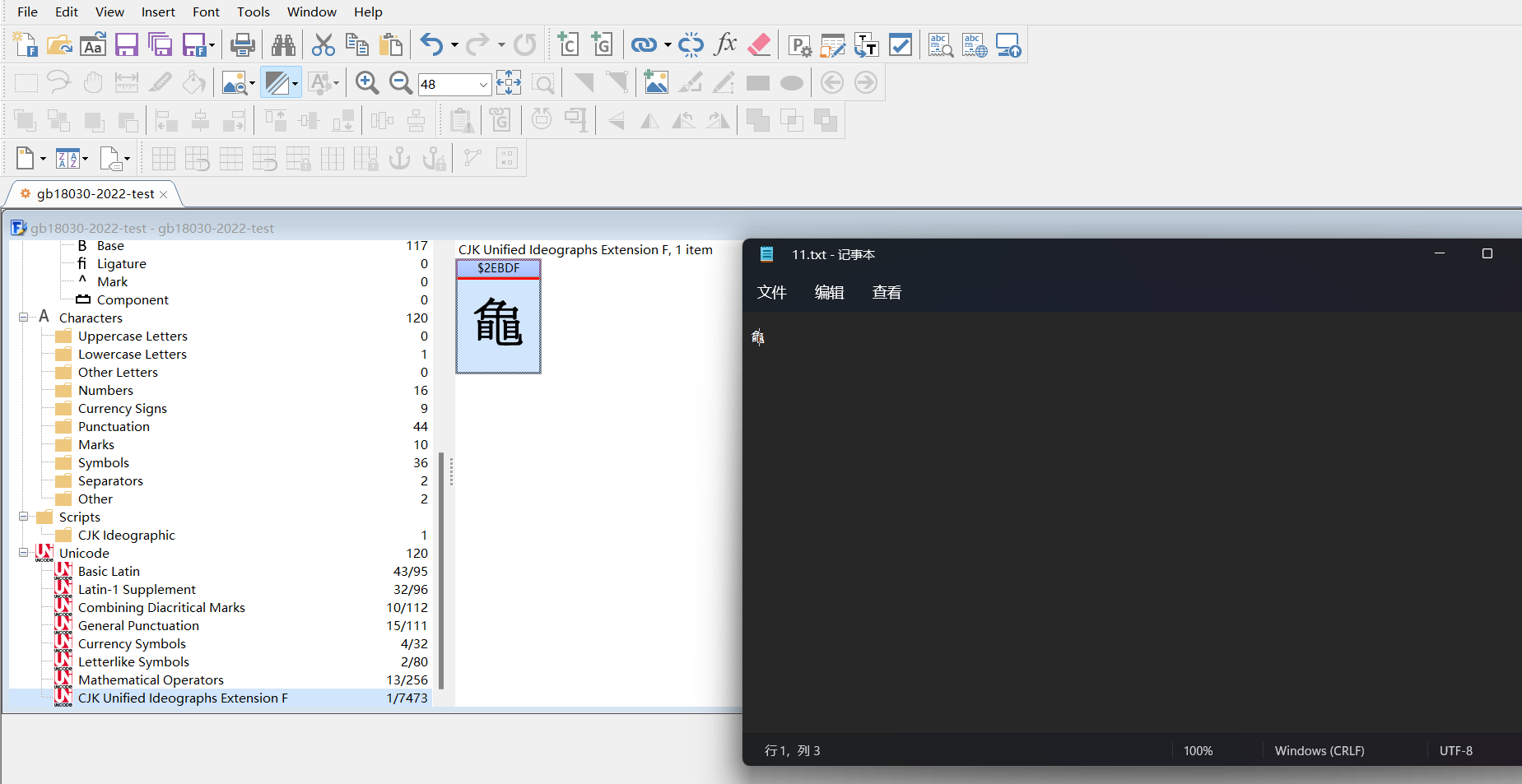
9. GB18030-2022不存在的字显示
2022版还是一个新的标准,系统上对一些文字可能无法显示
如:
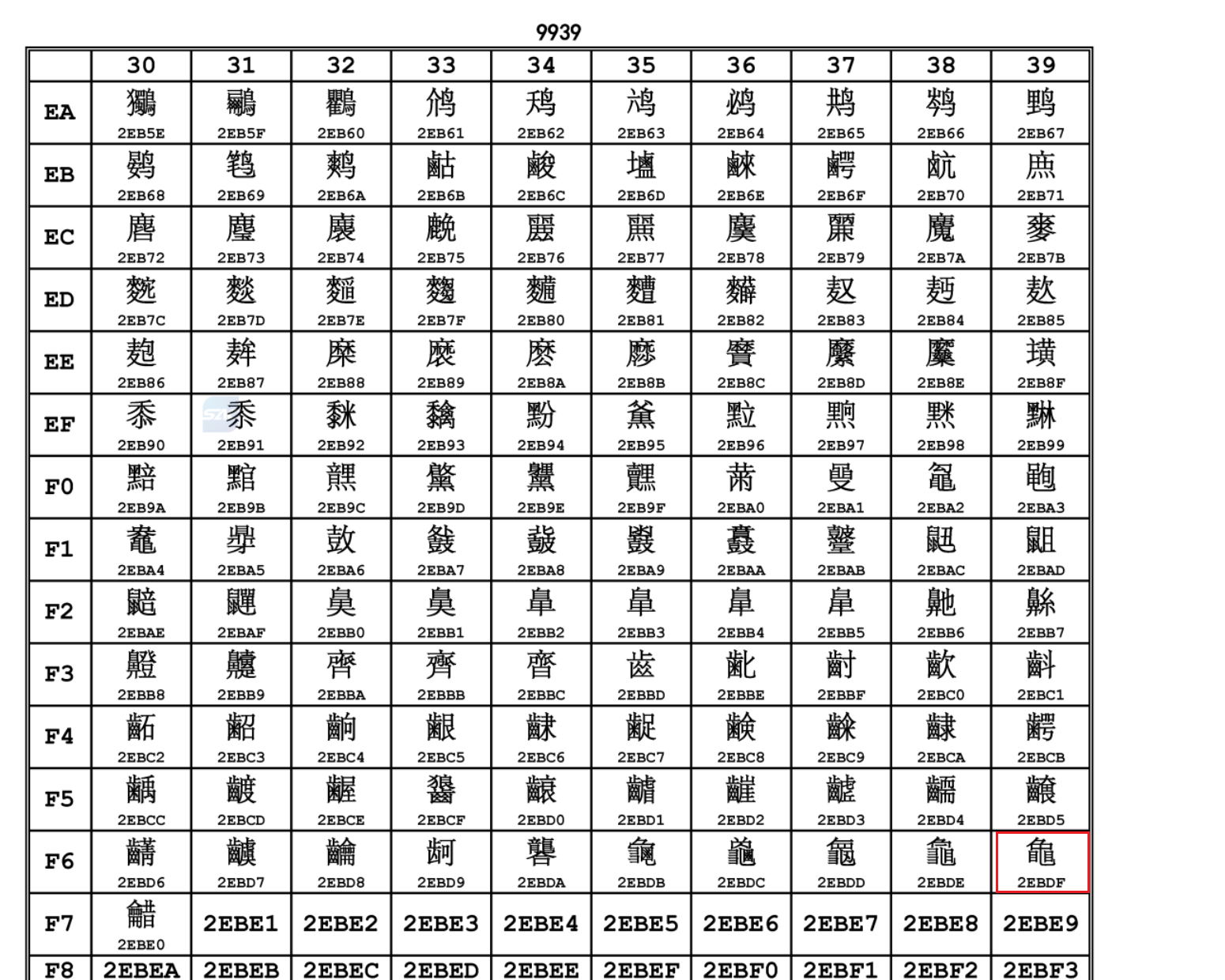
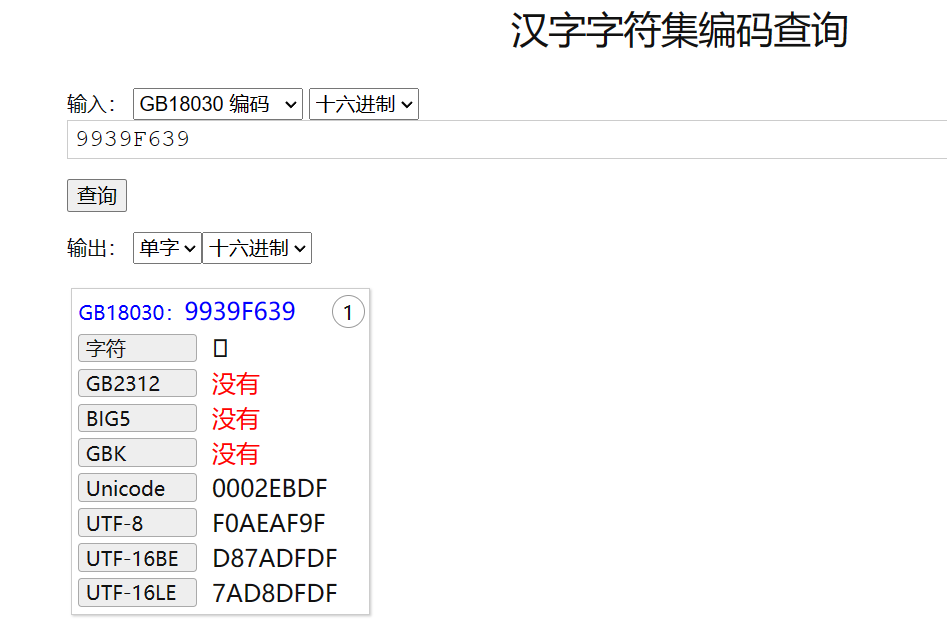
直接输入在记事本里是显示不了的
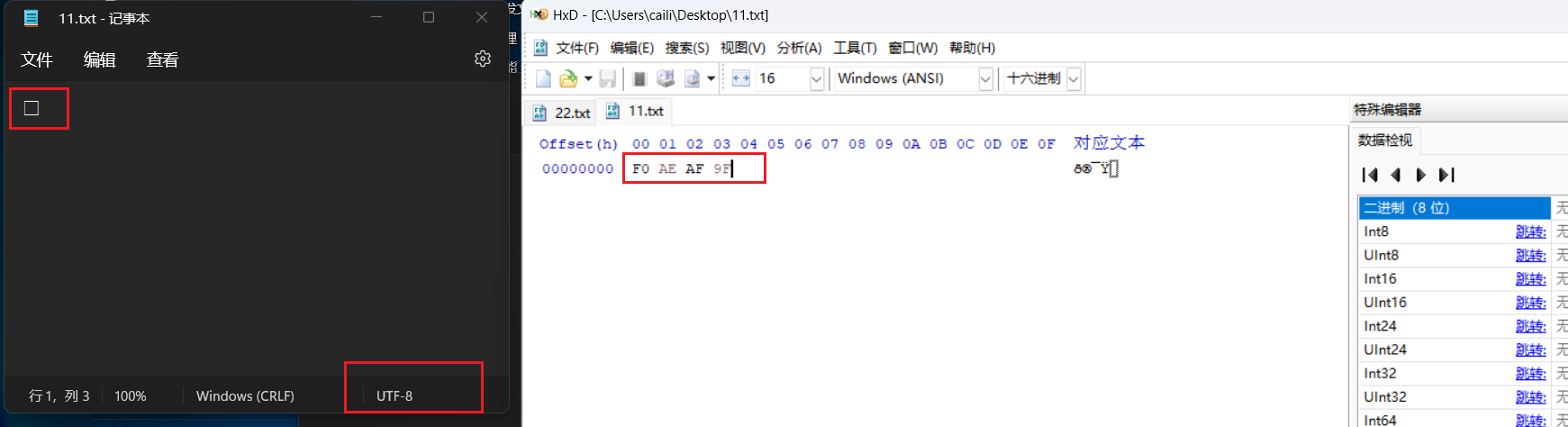
利用工具造个字,再选一下字体就显示了